Field notes for the Databricks Certified Spark Developer Exam
Notes for candidates who need a quick reference for the exam.

Certifications look amazing in your profiles and resumes, isn’t it. And trust me, a Google search can present you thousands of pages/blogs/git pages/articles on how to get the best results. Of course — then there are the infamous “dumps” — now available with lot of top learning websites — which is what many would consider as Bible instead of going through the pains of books and documentations.
However! there is no better way to prepare for a certification than practice and practice and practice harder. Practice makes us learn faster. When I started learning Spark from a Python Pandas background, I felt dizzy — so much to think about with DataFrames? Seriously? But then I realized the beauty when I could finish a job for a 7M dataset in 10 mins just by changing a parameter or two in Spark — while Pandas crashed. Big Data after all. Practice made me confident.
But along with practice, there is always a need to know “what should I know” or “how much should I know” — and that would lead you naturally to “how do I know”
So here are some notes on the Databricks Certified Spark Developer exam which may help aspirants to some extent along with the practice. I know this is one of thousands available, but I hope it may help someone in need.
Note that I will refer to the PySpark version of the test — not the Scala version.
Exam Details
- 60 Questions- All are Multiple Choice, No Programming
- 120 minutes, 70% to Pass (42/60 questions must be correct)
Exam Coverage
- Spark Architecture : Conceptual and Applications ~ 30%
Cluster architecture: nodes, drivers, workers, executors, slots - how they relate
Spark execution hierarchy: applications, jobs, stages, tasks
Job recovery and parallelism — number of nodes/cores etc.
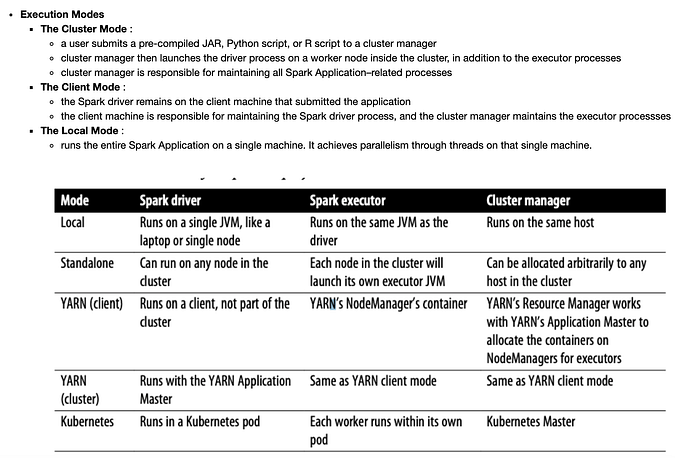
Execution modes and Deployment modes
Memory optimization and Garbage collection — high level concepts and configurations
Partitioning
Shuffling
Lazy evaluation
Transformations vs Actions
Narrow vs Wide transformations
Persistence and Storage levels
Configuration Parameters
AQE (Adaptive Query Execution) — new in spark 3.0 version of exam
Repartitioning and Coalescing
Joins — Sort Merge and Broadcasting
- Dataframe API and Spark SQL: ~ 70%
Spark SQL Plans and components used in each plan stage
Concept of Spark Session
Dataframe Reader and Writer methods — various options for reader and writer
Creation of Dataframes
Slice and Dice Dataframes (select, filter, etc.)
Column manipulation (casting, creating columns, manipulating existing columns, complex column types)
String manipulation (Splitting strings, regex)
Performance-based operations (repartitioning, shuffle partitions, caching)
Combining Dataframes (joins, broadcasting, unions, etc)
Working with dates and timestamps (extraction, formatting, etc)
Aggregations
Miscellaneous (sorting, missing values, typed UDFs, value extraction, sampling)
Exam Tips :
- Be very clear on architecture — questions are tricky with keywords which may easily confuse — especially areas like : execution modes vs deployment modes, logical vs physical plans, cores vs nodes vs executors, driver vs cluster manager, actions and transformations, operations requiring vs not requiring shuffles, cache vs persist default storage levels etc. Orchestration of components in creating spark jobs — how driver, cluster manager and executor work with each other and what are their responsibilities. Expect questions on application of your knowledge of architecture — like how many nodes/cores would make a good cluster for no loss of data in the event of failure, how many partitions would you suggest etc.
- Practice more and more for DataFrame operation syntaxes — this is extremely important and covers a lot of questions. Like — order of operations while reading and repartitioning a parquet file or a csv file, conversion of timestamps, how to use column objects, how to use expr and selectExpr, dataframe functions vs spark SQL functions and how to use them correctly, timestamp datatypes and their conversions, syntaxes for join and aggregations, new column additions and renaming columns.
And now — let’s see some field notes (PySpark):
These notes below are consolidated from Spark Docs and my own practice notebooks. For further details, check documentations and remember —
“do it yourself before your believe in it”
Spark Architecture :


Configuration Parameters:
A comprehensive list is in https://spark.apache.org/docs/latest/configuration.html#available-properties, but some of them worth mentioning are here:
- spark.sql.files.maxPartitionBytes 134217728 (128 MB)
The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. - spark.default.parallelism : Number of cores in machine or 2 whichever is larger Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user.
- spark.sql.autoBroadcastJoinThreshold : 10485760 (10 MB) Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE tablename COMPUTE STATISTICS noscan has been run.
Spark Session Object :
Creation of spark session object.
- Importing Spark libraries / finding PySpark: findspark can find the actual path of the spark binaries if there is a separate installation of spark in your system and you know the SPARK_HOME
# using findspark to find spark installation instead of local pyspark module
import os
import findspark
os.environ['SPARK_HOME'] = "/usr/local/Cellar/apache-spark/3.1.2/libexec"
findspark.init()from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
- Spark Session Object: Note the different config options which can be passed while creating the Spark Session. Also note which config elements can be changed dynamically (like spark.sql.shuffle.partitions)
spark = SparkSession \
.builder \
.appName("PySparkNotes") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()Note below is NOT right: Spark Session is a class and builder is an attribute, not a method. They need to be referenced without ().
spark = SparkSession() \
.builder() \
.appName("PySparkNotes") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()Spark Data Types:
https://spark.apache.org/docs/latest/sql-ref-datatypes.html
Check the spark API accessor data type like IntegerType() or StringType(). There may be syntax questions or questions on DataFrame schema asking to fill data type — some may have “integer” instead of IntegerType() or “str” instead of StringType(). Make sure the correct type name is known. Also, watch out for the NaN semantics section in the page above to understand how NaN behaves in DataFrame operations.
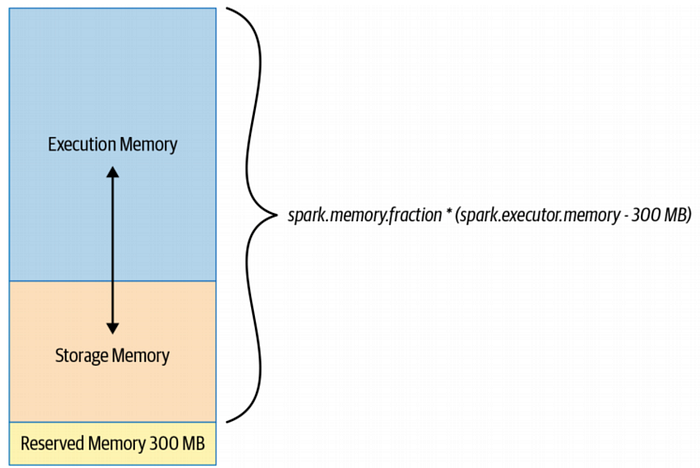
Memory and GC:


Planning in Spark:

AQE (Adaptive Query Execution) in spark 3.0:


Caching and Persistence:

Databases and Managed and Unmanged Tables in Spark SQL


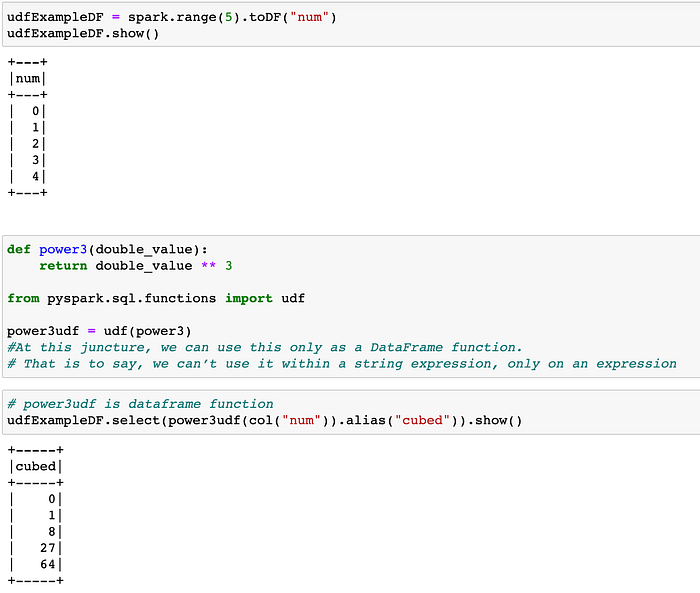
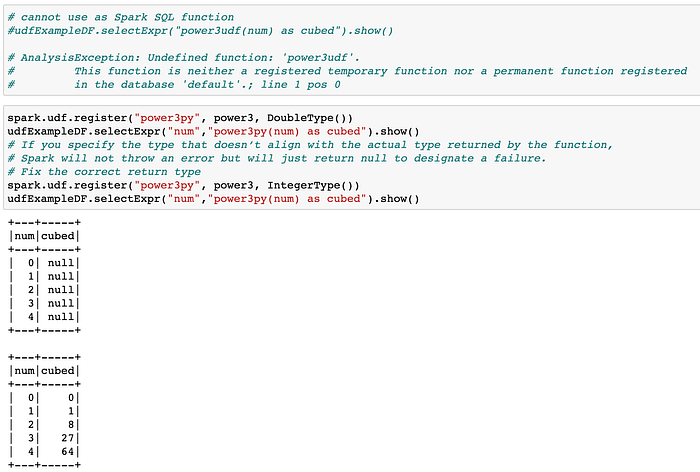
UDF(User Defined Functions)

The DataFrame API
Creation of DataFrame
Using createDataFrame method:
# with schema
schema = StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])df2 = spark.createDataFrame([], schema)
df2.printSchema()
df2.show()root
|-- firstname: string (nullable = true)
|-- middlename: string (nullable = true)
|-- lastname: string (nullable = true)
+---------+----------+--------+
|firstname|middlename|lastname|
+---------+----------+--------+
+---------+----------+--------+# without schema
df3 = spark.createDataFrame([], StructType([]))
df3.printSchema()
df3.show()
Using toDF() method:
pyspark.sql.DataFrame.toDF(*cols). Returns a new DataFrame that with new specified column names
# spark.range(n) gives a Dataframe of n numbers 0 to n-1 with column name id
spark.range(5).show(4)
+---+
| id|
+---+
| 0|
| 1|
| 2|
| 3|
+---+
only showing top 4 rows# to rename the "id" column, we can use toDF(col) function
myRange = spark.range(1000).toDF("number")# get number of partitions
myRange.rdd.getNumPartitions()myRange.show(5)
+------+
|number|
+------+
| 0|
| 1|
| 2|
| 3|
| 4|
+------+
only showing top 5 rows
From rdd:
columns = ["language","users_count"]
data = [("Java", "20000"), ("Python", "100000"), ("Scala", "3000")]# rdd is created from the list of tuples with the parallelize method of the spark context
rdd = spark.sparkContext.parallelize(data)rdd.take(3)[('Java', '20000'), ('Python', '100000'), ('Scala', '3000')]# default column names are _1, _2 etc
dfFromRDD1 = rdd.toDF()
dfFromRDD1.printSchema()root
|-- _1: string (nullable = true)
|-- _2: string (nullable = true)# set column names
dfFromRDD2 = spark.createDataFrame(rdd).toDF(*columns)
dfFromRDD2.printSchema()root
|-- language: string (nullable = true)
|-- users_count: string (nullable = true)# without schema using list of tuples and column name list
dfa = spark.createDataFrame(
[
(1, "foo"), # create your data here, be consistent in the types.
(2, "bar"),
],
["id", "label"] # add your column names here
)dfa.show()+---+-----+
| id|label|
+---+-----+
| 1| foo|
| 2| bar|
+---+-----+
From a specified Schema (Recommended way) using createDataFrame (Example shows nested schema — for name fields):
from pyspark.sql.types import StructType,StructField, StringType, IntegerType# nested data
structureData = [
(("James","","Smith"),"36636","M",3100),
(("Michael","Rose",""),"40288","M",4300),
(("Robert","","Williams"),"42114","M",1400),
(("Maria","Anne","Jones"),"39192","F",5500),
(("Alexa","","Jones"),"39193","F",5500),
(("Mike","",""),"415243","M",None),
(("Kiran","","Walters"),"30901","F",None),
(("Jen","Mary","Brown"),None,"F",-1)
]# structure specification - note nested structure and types# StructType([
# StructField('name_of_column', DataType(), Nullable?),
# ]
# )structureSchema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField('id', StringType(), True),
StructField('gender', StringType(), True),
StructField('salary', IntegerType(), True)
])df2 = spark.createDataFrame(data=structureData,schema=structureSchema)df2.printSchema()root
|-- name: struct (nullable = true)
| |-- firstname: string (nullable = true)
| |-- middlename: string (nullable = true)
| |-- lastname: string (nullable = true)
|-- id: string (nullable = true)
|-- gender: string (nullable = true)
|-- salary: integer (nullable = true)df2.show(truncate=False)+--------------------+------+------+------+
|name |id |gender|salary|
+--------------------+------+------+------+
|{James, , Smith} |36636 |M |3100 |
|{Michael, Rose, } |40288 |M |4300 |
|{Robert, , Williams}|42114 |M |1400 |
|{Maria, Anne, Jones}|39192 |F |5500 |
|{Alexa, , Jones} |39193 |F |5500 |
|{Mike, , } |415243|M |null |
|{Kiran, , Walters} |30901 |F |null |
|{Jen, Mary, Brown} |null |F |-1 |
+--------------------+------+------+------+
The DataFrame Reader : spark.read()
DataFrameReader.format(…).option(“key”, “value”).schema(…).load()

# Reading a csv file - all of these methods work the same for all the different formatsdf = spark.read.csv(csv_file_path)
df = spark.read.format('csv').options(header=True,inferSchema=True).load(csv_file_path)
df = spark.read.format('csv').options(header='True',inferSchema='True').load(csv_file_path)
df = spark.read.format('CSV').options(header='true',inferSchema='true').load(csv_file_path)
df = spark.read.csv(file_path, header=True)
df = spark.read.csv(file_path, header='true')# Reading a json file
df = spark.read.json(json_file_path)# Reading a text file
df = spark.read.text(text_file_path)# Reading a parquet file
df = spark.read.load(parquet_file_path) # or
df = spark.read.parquet(parquet_file_path)# Reading a delta lake file
df = spark.read.format("delta").load(delta_lake_file_path)# Query from parquet as a table directly
df = spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
The DataFrame Writer : spark.write()
DataFrameWriter.format(…).option(…).partitionBy(…).bucketBy(…).sortBy( …).save()
Default format for save is Parquet.

df.write.format("csv").mode("overwrite").save(outputPath/file.csv)df.write.format("json").mode("overwrite").save(outputPath/file.json)df.write.format("parquet").mode("overwrite").save("outputPath")df.write.format("delta").partitionBy("someColumn").save(path)# Write file to disk in parquet format partitioned by year - overwrite any existing file
df.write.partitionBy('year').format('parquet').mode('overwrite').save(parquet_file_path)# Write file to disk in parquet format partitioned by year - append to an existing file
df.write.partitionBy('year').format('parquet').mode('append').save(parquet_file_path)# Write data frame as a Hive table
df.write.bucketBy(10, "year").sortBy("avg_ratings").saveAsTable("films_bucketed")# Read and save in different formats
df = spark.read.load("examples/src/main/resources/people.json", format="json")
df.select("name", "age").write.save("namesAndAges.parquet", format="parquet")
Take , Collect, Show, Limit
- df.take(n) = Returns the first n rows as a list of Row.
- df.tail(n) = Returns the last n rows as a list of Row.
- df.collect() = action function is used to retrieve all elements from the dataset (RDD/DataFrame/Dataset) as a Array of Row to the driver program.
- df.collect_list() = function returns all values from an input column with duplicates.
- limit() is a transformation and returns a DataFrame.
- take(), first() and collect () — All return the data to the driver.
df2.show(3)+--------------------+-----+------+------+
| name| id|gender|salary|
+--------------------+-----+------+------+
| {James, , Smith}|36636| M| 3100|
| {Michael, Rose, }|40288| M| 4300|
|{Robert, , Williams}|42114| M| 1400|
+--------------------+-----+------+------+
only showing top 3 rows# show number of partitions - default is the number of cores in my local machine as I am using local mode
df2.rdd.getNumPartitions()16# take first n records as a list
df2.take(1)[Row(name=Row(firstname='James', middlename='', lastname='Smith'), id='36636', gender='M', salary=3100)]# take last n records
df2.tail(1)[Row(name=Row(firstname='Jen', middlename='Mary', lastname='Brown'), id='', gender='F', salary=-1)]# collect all records as a list of rows - get to Master Node (costly operation and should be minimized using filters before) df2.collect()[Row(name=Row(firstname='James', middlename='', lastname='Smith'), id='36636', gender='M', salary=3100),
Row(name=Row(firstname='Michael', middlename='Rose', lastname=''), id='40288', gender='M', salary=4300),
Row(name=Row(firstname='Robert', middlename='', lastname='Williams'), id='42114', gender='M', salary=1400),
Row(name=Row(firstname='Maria', middlename='Anne', lastname='Jones'), id='39192', gender='F', salary=5500),
Row(name=Row(firstname='Alexa', middlename='', lastname='Jones'), id='39193', gender='F', salary=5500),
Row(name=Row(firstname='Jen', middlename='Mary', lastname='Brown'), id='', gender='F', salary=-1)]# these two are same
df2.collect()[0] == df2.take(1)[0]# select single column and collect
df2.select("salary").collect()# different data types for collect - collect() returns list of Rows
print(type(df2.select(sum("salary")).collect()))
print(type(df2.select(sum("salary")).collect()[0]))<class 'list'>
<class 'pyspark.sql.types.Row'>df2.select(sum("salary")).collect()[0]Row(sum(salary)=19799)# to get sum as a scalar value: collect(list of rows) --> [0] (one row) --> [0] (one column)
df2.select(sum("salary")).collect()[0][0]19799# collect_list and collect_set# get list of records in a column as a list to driver: collect_list(list of rows) --> [0] (one row) --> [0] (one column)
df2.select(collect_list("salary")).collect()[0][0][3100, 4300, 1400, 5500, 5500, -1]# get list of records in a column as a set to driver: collect_list(list of rows) --> [0] (one row) --> [0] (one column)
df2.select(collect_set("salary")).collect()[0][0][5500, -1, 4300, 1400, 3100]
Column Operations
This is an extremely important topic and covers a considerable part of the exam. Make sure proper syntax is known. Reading docs and practice is highly recommended for perfecting this.
column functions
from pyspark.sql.functions import expr, col, columndf2.select(col("name.firstname").alias("FirstName"), # using col
expr("name.lastname AS LastName"), # using expr and AS
expr("id"), # using expr
"salary", # using string column name
df2.gender # using df.colname
) \
.show()+---------+--------+-----+------+------+
|FirstName|LastName| id|salary|gender|
+---------+--------+-----+------+------+
| James| Smith|36636| 3100| M|
| Michael| |40288| 4300| M|
| Robert|Williams|42114| 1400| M|
| Maria| Jones|39192| 5500| F|
| Alexa| Jones|39193| 5500| F|
| Jen| Brown| | -1| F|
+---------+--------+-----+------+------+
Expression Test conditions — if / ifnull / in / isnull. Can be confusing in exam.
#if:
df2.selectExpr("name","salary","if(salary < 5000, salary * 0.20 , 0) as increment").show()#ifnull (like nvl):
df2.selectExpr("name","salary","ifnull(salary, 1000) as new_salary").show()#in:
df2.selectExpr("name","salary","name.firstname in ('Robert','James') as common_name").show()#isnull:
df2.selectExpr("name","salary","isnull(salary) as no_salary").show()
Expressions in DataFrame — Expr and SelectExpr:
# Use math operators in select
df2.select(col("salary") * 0.15).show()# We can use (*) within both select and selectExpr
df2.select("*").show()
df2.selectExpr("*").show()# Equivalent synataxes for expr and selectExprdf2.withColumn("salary_increment",expr("salary * 0.15")).show()
df2.selectExpr("*","salary * 0.15 as salary_increment").show()df2.select("*",expr("isnull(salary) as no_salary")).show()
df2.selectExpr("*","isnull(salary) as no_salary").show()# Simple expressions: get boolean value for ManagerGrade
df2.selectExpr("*","(salary > 3000) as ManagerGrade").show()# using case statements
df2.selectExpr("id", "salary","CASE WHEN salary between 0 and 3000 THEN 'Junior' ELSE 'Senior' END AS GRADE").show()df2.selectExpr("id", "salary","if (salary >=0 and salary <= 3000,'Junior','Senior') AS GRADE").show()# using if statements
df2.selectExpr("name","if(salary < 5000, salary * 0.20 , 0) as increment").show()# multiple elements in col as array
df2.selectExpr("id","array(name.firstname,name.lastname) as personalDetails").show()+-----+------------------+
| id| personalDetails|
+-----+------------------+
|36636| [James, Smith]|
|40288| [Michael, ]|
|42114|[Robert, Williams]|
|39192| [Maria, Jones]|
|39193| [Alexa, Jones]|
| | [Jen, Brown]|
+-----+------------------# multiple elements as struct - note diff from prev case
df2.selectExpr("id","struct(name.firstname,name.lastname) as personalDetails").show()+-----+------------------+
| id| personalDetails|
+-----+------------------+
|36636| {James, Smith}|
|40288| {Michael, }|
|42114|{Robert, Williams}|
|39192| {Maria, Jones}|
|39193| {Alexa, Jones}|
| | {Jen, Brown}|
+-----+------------------+
Handling NaN
dropna function:
- how ‘any’ or ‘all’. If ‘any’, drop a row if it contains any nulls. If ‘all’, drop a row only if all its values are null.
- thresh default None If specified, drop rows that have less than thresh non-null values. This overwrites the how parameter
- subset : optional list of column names to consider.
- fill all columns with the same value: df.fillna(value). Eg: df.na.fill(0)
- pass a dictionary of column/value: df.fillna(dict_of_col_to_value). Eg: df.fillna({‘col’:’4'})
- pass a list of columns to fill: df.fillna(value, subset=list_of_cols). Eg: df.fillna(0, subset=[‘a’, ‘b’])
- fillna() is an alias for na.fill() so they are the same.
# convert empty string to null
df3 = df2.withColumn('id', when(col('id') == '', None).otherwise(col('id')))
df3.show()+--------------------+-----+------+------+
| name| id|gender|salary|
+--------------------+-----+------+------+
| {James, , Smith}|36636| M| 3100|
| {Michael, Rose, }|40288| M| 4300|
|{Robert, , Williams}|42114| M| 1400|
|{Maria, Anne, Jones}|39192| F| 5500|
| {Alexa, , Jones}|39193| F| 5500|
| {Jen, Mary, Brown}| null| F| -1|
+--------------------+-----+------+------+# use fillna or na.fill
df3.fillna("N/A").show()
df3.na.fill("N/A").show()+--------------------+-----+------+------+
| name| id|gender|salary|
+--------------------+-----+------+------+
| {James, , Smith}|36636| M| 3100|
| {Michael, Rose, }|40288| M| 4300|
|{Robert, , Williams}|42114| M| 1400|
|{Maria, Anne, Jones}|39192| F| 5500|
| {Alexa, , Jones}|39193| F| 5500|
| {Jen, Mary, Brown}| N/A| F| -1|
+--------------------+-----+------+------+# Specify fillna for different columns
df = df.fillna({
'gender': 'Unknown',
'salary': 0,
})
Filter DataFrame — where and filter
# all these will show same outputdf2.where(expr("salary > 4000")).show()
df2.filter(expr("salary > 4000")).show()df2.where(df2.salary > 4000).show()
df2.filter(df2.salary > 4000).show()# combining filters with | and & and using variables for filter
filter1 = col("gender") == "F"
filter2 = df2.salary >= 4000df2.where(filter1 | filter2).show() # And condition
df2.where(filter1 & filter2).show() # Or condition
count distinct — 4 ways of doing
# aggregate count on a column after distinct
df2.select("salary").distinct().agg(count("salary")).show()# aggregate on entire dataframe using countDistinct
df2.agg(countDistinct("salary")).show() # use countDistinct sql function
df2.select(countDistinct("salary")).show()# use sql count(distinct col) format
df2.selectExpr("count(distinct salary)").show()
grouping and aggregation
# Get combinations of values using collect_list as part of aggregation
df2.selectExpr("*","name.lastname as Lname") \
.groupBy("Lname") \
.agg(collect_list(array("gender","salary")).alias("Collection")) \
.show(truncate = False)+--------+----------------------+
|Lname |Collection |
+--------+----------------------+
|Jones |[[F, 5500], [F, 5500]]|
|Williams|[[M, 1400]] |
|Smith |[[M, 3100]] |
|Brown |[[F, -1]] |
| |[[M, 4300]] |
+--------+----------------------+
df2.groupBy(df2.name.lastname).agg({"*": "count"}).show()+--------------+--------+
|name[lastname]|count(1)|
+--------------+--------+
| Jones| 2|
| Williams| 1|
| Smith| 1|
| Brown| 1|
| | 1|
+--------------+--------+
# using different types of agg functions and formats
df2.groupBy("gender") \
.agg( expr("count(*) as total_records_expr"), \
count("*").alias("total_records"), \
expr("sum(salary) as sum_salary_expr"), \
sum("salary").alias("sum_salary"), \
avg("salary").alias("avg_salary"), \
max("id").alias("max_id"), \
min("id").alias("min_id")) \
.show()+------+------------------+-------------+---------------+----------+------------------+------+------+
|gender|total_records_expr|total_records|sum_salary_expr|sum_salary| avg_salary|max_id|min_id|
+------+------------------+-------------+---------------+----------+------------------+------+------+
| F| 4| 4| 10999| 10999|3666.3333333333335| 39193| 30901|
| M| 4| 4| 8800| 8800|2933.3333333333335| 42114| 36636|
+------+------------------+-------------+---------------+----------+------------------+------+------+df2.groupBy("gender") \
.agg(collect_set("Salary"), collect_list("salary")) \
.show()+------+-------------------+--------------------+
|gender|collect_set(Salary)|collect_list(salary)|
+------+-------------------+--------------------+
| F| [5500, -1]| [5500, 5500, -1]|
| M| [4300, 1400, 3100]| [3100, 4300, 1400]|
+------+-------------------+--------------------+# Window functions
from pyspark.sql.window import WindowwindowSpec = Window \
.partitionBy("gender") \
.orderBy(desc("salary")) \
.rowsBetween(Window.unboundedPreceding, Window.currentRow)df2.select("gender","salary", rank().over(windowSpec).alias("rnk")).show()
orderBy
df2.orderBy(expr("salary")).show()
df2.orderBy(expr("salary").asc()).show() # default is ascending. Nulls come first
df2.orderBy(expr("salary").asc_nulls_last()).show() # to make nulls go to enddf2.orderBy(expr("salary").desc()).show()
df2.orderBy(expr("salary").desc_nulls_last()).show() # same as desc. desc sorts null at end
df2.orderBy(expr("salary").desc_nulls_first()).show() # to make nulls come first for desc# Specificiation of ascending and descending in 3 ways
df2.orderBy(col("salary").desc()).show()
df2.orderBy(expr("salary").desc()).show()
df2.orderBy(expr("salary"),ascending = False).show()# mixed order by
df2.orderBy(col("salary").desc(), col("gender").asc()).show()
type cast
df2.withColumn("id",col("id").cast(StringType())).printSchema()
df2.withColumn("id",col("id").cast('string')).printSchema()
df2.withColumn("id",expr("id").cast('string')).printSchema()df2.select(col("id").cast("string")).alias("id").printSchema()
df2.select(col("id").cast(StringType())).alias("id").printSchema()
df2.select(expr("STRING(id)")).printSchema()df2.selectExpr("cast(id as string) as id").printSchema()
df2.selectExpr("STRING(id)").printSchema()
dates and timestamps
#date_format()
df.select(col("input"),
date_format(col("input"), "MM-dd-yyyy").alias("date_format")
).show()#to_date()
df.select(col("input"),
to_date(col("input"), "yyy-MM-dd").alias("to_date")
).show()#datediff()
df.select(col("input"),
datediff(current_date(),col("input")).alias("datediff")
).show()#add_months() , date_add(), date_sub()
df.select(col("input"),
add_months(col("input"),3).alias("add_months"),
add_months(col("input"),-3).alias("sub_months"),
date_add(col("input"),4).alias("date_add"),
date_sub(col("input"),4).alias("date_sub")
).show()#current_timestamp()
df2.select(current_timestamp().alias("current_timestamp")
).show()#to_timestamp()
df2.select(col("input"),
to_timestamp(col("input"), "MM-dd-yyyy HH mm ss SSS").alias("to_timestamp")
).show()#extract hour/min/secdf3.select(col("input"),
hour(col("input")).alias("hour"),
minute(col("input")).alias("minute"),
second(col("input")).alias("second")
).show()# working with unix_timestamp: from timestamp to unix_timestampdf2 = df.select(
unix_timestamp(col("timestamp_1")).alias("timestamp_1"),
unix_timestamp(col("timestamp_2"),"MM-dd-yyyy HH:mm:ss").alias("timestamp_2"),
unix_timestamp(col("timestamp_3"),"MM-dd-yyyy").alias("timestamp_3"),
unix_timestamp().alias("timestamp_4")
)# working with unix_timestamp: from unix_timestamp to timestampdf3=df2.select(
from_unixtime(col("timestamp_1")).alias("timestamp_1"),
from_unixtime(col("timestamp_2"),"MM-dd-yyyy HH:mm:ss").alias("timestamp_2"),
from_unixtime(col("timestamp_3"),"MM-dd-yyyy").alias("timestamp_3"),
from_unixtime(col("timestamp_4")).alias("timestamp_4")
)
Create Unmanaged tables in spark sql using a file (like an external table)
spark.sql("DROP TABLE IF EXISTS delta_table_name")spark.sql("CREATE TABLE delta_table_name USING DELTA LOCATION '/path/to/delta_directory'")
End Note:
While the areas covered by the exam is way more extensive than these notes, it can serve as a good starting point for the long journey.
Wish you success and remember — practice is the key to success! Not “dumps” :):):)
Happy Sparkling
If you find any mistakes here, please feel free to ping me in linked in.
- DataFrames
